
TL;DR
The Digital Omnibus on AI has reached provisional political agreement, deferring high-risk obligations for most Annex III systems to December 2027. The core requirements have not changed, and neither has the foundational problem: most enterprises cannot produce an accurate inventory of the AI components embedded in their software. An AI Bill of Materials is not a byproduct of compliance. It is where compliance has to begin.
What the EU AI Act Omnibus changes for AIBOM compliance
What did the Omnibus actually change?
On 7 May 2026, the European Parliament and the Council of the EU reached provisional political agreement on the Digital Omnibus on AI, the first set of targeted amendments to Regulation (EU) 2024/1689 since its adoption. The agreement has not yet been formally adopted — the European Parliament plenary vote is expected this month, with formal Council adoption and publication in the Official Journal anticipated in July, ahead of the 2 August 2026 deadline. Until publication in the Official Journal, the original text of the Regulation remains applicable law.
The most significant change is a staggered deferral of high-risk obligations. Annex III high-risk AI systems — use-case-based classifications covering areas such as employment, education, essential services and law enforcement — have their obligations deferred from 2 August 2026 to 2 December 2027, a delay of 16 months. High-risk AI embedded in regulated products under Annex I, including medical devices, machinery and toys, is deferred from 2 August 2027 to 2 August 2028. The grace period for AI-generated content transparency under Article 50 has been shortened from six months to three, with watermarking and labelling obligations due on 2 December 2026.
What did not change: the risk-based classification architecture, the four-tier system, the general-purpose AI obligations under Article 53, the conformity assessment regime, the AI Office’s oversight role, and the penalty structure under Article 99. The Omnibus moved timelines. It did not move the underlying framework.
Why does the delay not resolve the inventory problem?
The instinct to treat an extended deadline as permission to deprioritise preparation is understandable but operationally counterproductive. Article 11 of the Regulation requires providers of high-risk AI systems to maintain technical documentation that describes the system’s components, the data used in development, and the methods and tools applied. That documentation depends on knowing, at code level, what AI components are present in the system being placed on the market.
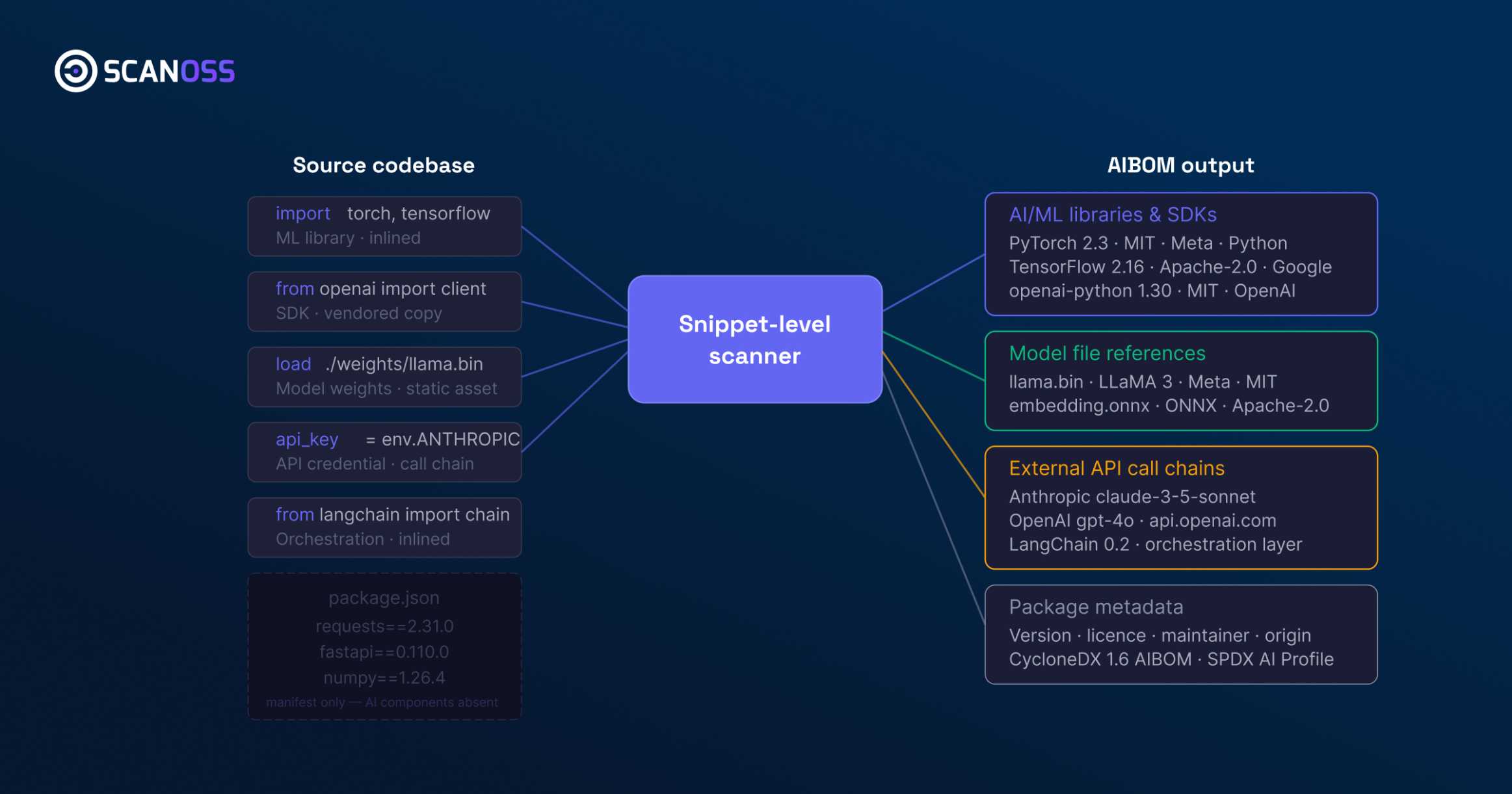
This is a visibility problem. AI and ML capability is now distributed throughout enterprise software in ways that do not surface at the manifest boundary. A production application may include open source ML libraries such as PyTorch or TensorFlow that are vendored rather than declared, model files distributed inside containers, API credentials that reach external large language model providers, and orchestration code from frameworks such as LangChain inlined into application logic. None of these are reliably captured by dependency manifests. Most of them are invisible to the compliance and legal functions that own the AI Act response.
The 16-month delay for Annex III systems does not create 16 months of slack. It creates 16 months in which to build the evidence base that any future audit, conformity assessment or national competent authority enquiry will request. Evidence assembled under deadline pressure, from a standing start, against a December 2027 date, will carry less weight than a documented inventory that has been maintained continuously from mid-2026. The same logic that made point-in-time SBOMs insufficient under the CRA applies here.
What should an AIBOM actually contain?
An AI Bill of Materials is the structured inventory of AI and ML components present in a software system. Its function under the EU AI Act is to provide the component-level evidence that Article 11 technical documentation, Article 50 transparency obligations and Article 53 general-purpose AI training-content summaries require but cannot themselves generate.
A complete AIBOM should document: AI/ML libraries and SDKs by component, version, licence and origin; model files and weights referenced or embedded in the codebase; API credentials and call chains that reach external AI providers, with identification of which model and provider each credential addresses; and package metadata sufficient to establish provenance and assess downstream licence obligations.
Two machine-readable AIBOM formats are currently in active use. OWASP CycloneDX 1.6 includes a dedicated AI BOM component type and is consumable by OWASP Dependency-Track and other SCA aggregators. The SPDX AI BOM Profile extends the SPDX 3.0 specification to cover AI system attributes. Both formats are supported under the Regulation’s technical documentation expectations; CycloneDX 1.6 additionally aligns with the CRA’s SBOM mandate, allowing a single scan to address both obligations where AI components are present.
What neither format can compensate for is incomplete detection at the source. An AIBOM generated from manifest files alone will miss vendored components, inlined SDK calls, and model files that are stored as static assets rather than declared as dependencies. Snippet-level detection — matching source code against a knowledge base of known AI/ML components rather than relying on package declarations — is the detection method that closes this gap.
What does this mean for organisations currently in scope?
The Omnibus changes the enforcement calendar for high-risk AI systems under Annex III. It does not change the scope of what must be documented, and it does not affect the Article 50 obligations for AI-generated content transparency, which remain on the original schedule for most use cases. Organisations that have already begun mapping their AI component footprint should continue without interruption. Those that have not should treat the Omnibus not as a reprieve but as the window in which to build the inventory that compliance depends on.
The practical starting point is the same in either case: run a code-level scan of the systems in scope, not a dependency manifest audit. Identify every AI/ML library, SDK, model reference and external API call present in the codebase. Output the result in a machine-readable AIBOM format that can feed technical documentation, procurement portals and SCA aggregators as the compliance programme matures.
SCANOSS supports this process through the AI governance dataset, built on the AI Finder. Detection operates at snippet level across 12 programming languages and more than 150 AI/ML packages. Output is produced in both CycloneDX 1.6 AIBOM and SPDX AI BOM Profile formats, ready to feed Dependency-Track, internal governance dashboards and Article 11 technical file evidence. Where the use case requires it, the Encryption dataset and Licence dataset attach to the same scan, supporting quantum-readiness planning and licence obligation mapping in parallel.
Organisations seeking to understand their AI component footprint ahead of either the August 2026 or December 2027 dates are welcome to request a demonstration or contact the SCANOSS team directly.


