
If you spend enough time around software supply chain programmes, you start to see a familiar pattern.
Most organisations do not arrive at their current SCA platform by accident. The original selection usually involved careful evaluation, internal debate, and a series of practical trade-offs. The chosen tool was good enough for the environment at the time.
But environments do not stand still.
A few years later, teams often find themselves in a different position. Licence costs may have increased. CI/CD pipelines may have evolved. Development practices may have shifted. New transparency requirements may have appeared. What once fit reasonably well can begin to feel increasingly rigid.
At that point, many organisations start to look again. They speak with other vendors. They run comparisons. Sometimes they even identify an alternative that appears technically stronger or operationally cleaner.
And then the process slows down.
Not because teams cannot see a better option, but because changing an embedded SCA platform is rarely just a tooling decision. It is an operational one. The deeper the existing tool is wired into pipelines, policies, and reporting workflows, the higher the perceived risk of touching it.
This is where many SCA transitions lose momentum, at the point where migration becomes real.
What tends to happen in the real world?
From the outside, SCA migration can look like a straightforward tooling exercise. Inside a production environment, it rarely behaves that way.
First, the need for change is usually legitimate, but ownership of delivery risk is often unclear. Security teams may want better visibility and fewer blind spots. Engineering teams may be pushing for reduced pipeline friction. Procurement may be under pressure to reassess long-term cost. Yet once migration becomes concrete, responsibility becomes diffuse.
Second, the dominant concern is not loss of scanning capability. It is operational disruption. When SCA enforcement is embedded into CI/CD gates, even a well-planned change can introduce uncertainty around build stability, release timing, or policy behaviour. For most organisations, that uncertainty outweighs tooling improvements.
Third, teams often begin with a lift-and-shift mindset. The initial assumption is that the new platform should replicate the existing tool’s behaviour exactly. In practice, this expectation creates friction quickly. Detection models differ. Policy engines differ. Reporting structures differ. Functional equivalence must be demonstrated in context.
Fourth, many programmes invest heavily in assessment but stop short of controlled proof. Workshops and evaluations help narrow options, but they rarely reduce delivery risk on their own. Confidence tends to increase only when the new approach is observed running against the organisation’s own repositories and pipelines.
Fifth, enablement is frequently underestimated. Even when the target architecture is sound, adoption slows if delivery teams are not comfortable with the new workflow. In large environments, this alone can extend migration timelines significantly.
None of these patterns are unusual. Taken together, however, they explain why many SCA transitions remain in prolonged evaluation cycles.
Over time, I saw this pattern repeat often enough that it stopped looking like isolated project risk. Teams were not stuck because better tooling did not exist. They were stuck because the path between “what we have” and “what we want” was operationally unclear.
That observation is what led me to formalise the migration approach described here.
Why changing SCA platforms feels riskier than it should?
There’s a misconception that the “open source route” is inherently riskier.
In reality, the risk is changing the system you’ve built around your current vendor: the gates, the workflows, the exceptions, the reporting habits, the audit narrative.
At the same time, the wider ecosystem is moving steadily towards machine-readable transparency. SBOM adoption is a clear signal of this direction. OWASP’s guidance on SBOM implementation, for example, emphasises integrating SBOM generation and monitoring directly into CI/CD so that visibility becomes continuous rather than a one-off reporting exercise.
That shift has architectural consequences. Continuous transparency is easier to sustain in environments where detection, analysis, and policy enforcement are modular and independently verifiable.
As a result, many organisations are reassessing tightly coupled SCA platforms and exploring more composable approaches, favouring vendor-neutral stacks over monoliths.
The migration strategy that changes the equation
When organisations get stuck, it’s usually because they’re trying to decide in the abstract.
Parallel runs change the equation.
A parallel run is not “running two tools forever”. It’s a controlled period where you run the new approach alongside the current one, just long enough to answer a few hard questions with evidence:
- What do results look like on our code?
- What changes in the pipeline?
- Where do policies diverge?
- What’s noise, what’s signal, and what’s just different modelling?
- Because tooling models and policy engines differ, equivalence must be demonstrated rather than assumed. Parallel evaluation provides the evidence needed to validate that the new approach supports release, security, and compliance decisions.
Just as importantly, the existing SCA platform continues to provide full coverage during this phase. That continuity is what allows organisations to evaluate change without introducing unnecessary delivery risk.
A migration model that doesn’t rely on courage
Once the expectation of a clean cutover is removed, the shape of a workable migration becomes much clearer.
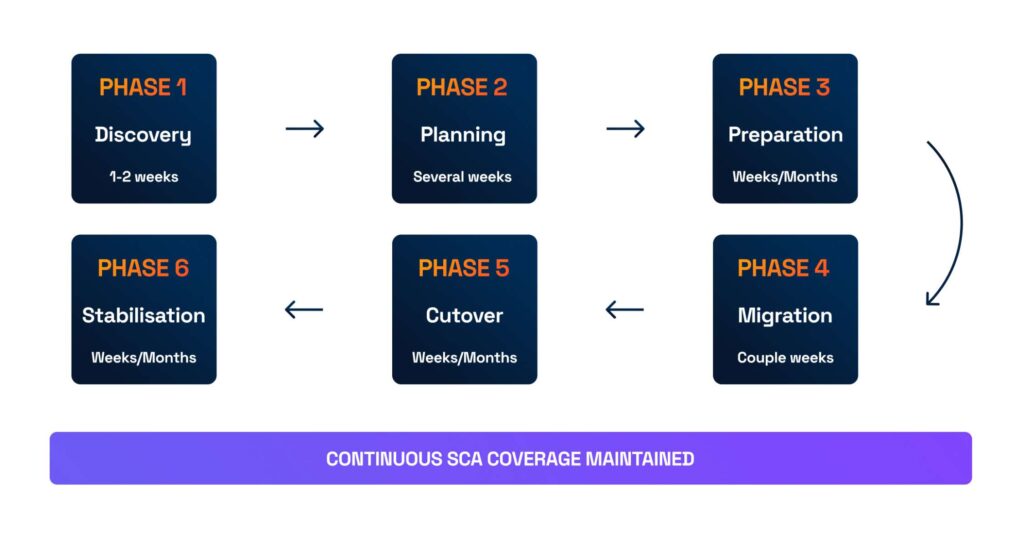
This is the same pattern we apply when helping teams move from proprietary SCA platforms to more composable tooling stacks: introduce change gradually, establish decision gates, and keep rollback explicit at every stage.
Where execution becomes the real challenge
Understanding the migration model is one thing. Applying it consistently across live pipelines, multiple teams, and existing governance structures is another.
In many environments, the real blocker is not the target architecture. It is the lack of a delivery plan that allows teams to move toward a more modular, vendor-neutral SCA stack without putting release confidence at risk.
This is one of the reasons open source–based and composable approaches are gaining traction. They give organisations greater visibility into detection behaviour, more flexibility in how components are combined, and fewer structural constraints when requirements evolve. Tools such as SCANOSS are often introduced at the detection layer because they fit naturally within this more decoupled model.
The challenge, however, is sequencing the transition safely.
This is typically the point where organisations ask for support — structuring the parallel phase, coordinating pipeline changes, and moving from evaluation to controlled rollout while maintaining continuous SCA coverage.
The deeper technical guide
To keep this article focused, I have placed the detailed implementation guidance in a separate document.
The downloadable framework covers:
- the phased migration model and decision gates
- how to structure parallel runs
- data handling and what not to migrate
- pipeline sequencing to avoid disruption
- policy continuity and rollback criteria
- prerequisites to have in place before starting
Most teams do not struggle to identify better SCA options, they struggle to move safely between them.
Download the Zero-Disruption SCA Migration Framework


