TL; DR
Most issues labelled as “false positives” in Software Composition Analysis are not detection errors. The code match is correct, but it is attributed incorrectly. This distinction matters because reducing misattribution requires improving context, not reducing detection. SCANOSS addresses this with structural fingerprinting, layered validation, and context-aware analysis.
What is misattribution in Software Composition Analysis?
Misattribution occurs when a detected piece of code is real, but linked to the wrong origin. The code exists in the scanned project, but the tool assigns it to the wrong component, version, or repository.
This is fundamentally different from a false positive. A false positive means the detected code is not present at all. In contrast, misattribution reflects a failure in interpretation, not detection.
This distinction is often overlooked, leading teams to assume their tooling is inaccurate when the issue is actually attribution precision. As a result, organisations focus on reducing matches instead of improving how matches are understood.
The scale of the problem comes from how open source evolves. Code is reused, forked, and modified across thousands of projects. The same function can appear in multiple contexts, making attribution inherently complex.
In large-scale environments, this is not an edge case. Modern codebases routinely include thousands of dependencies and transitive components, many of which share common origins or have been partially reused. Without precise attribution, even correct detections become operationally noisy.

Why are “false positives” often mislabelled?
Many SCA tools report matches that require manual review. These are frequently labelled as false positives because they create friction. However, in many cases, the match itself is correct. The issue is that the tool cannot confidently determine which project or version the code belongs to.
Traditional SCA tools rely on signatures or patterns. These approaches struggle when:
- Code is slightly modified
- Multiple projects share similar structures
- Forks diverge from original repositories
This leads to ambiguous results, where multiple potential attributions exist for a single match.
In practice, this ambiguity surfaces as duplicated findings, conflicting component suggestions, or matches that cannot be resolved without manual inspection. Teams often interpret this as tool inaccuracy, when it is actually a limitation in attribution depth.
The consequence is predictable: teams either spend time validating results or begin ignoring them. Both outcomes undermine the purpose of SCA, which is to provide reliable, actionable insight into software composition.
How does SCANOSS reduce misattribution?
Structural fingerprinting with Winnowing
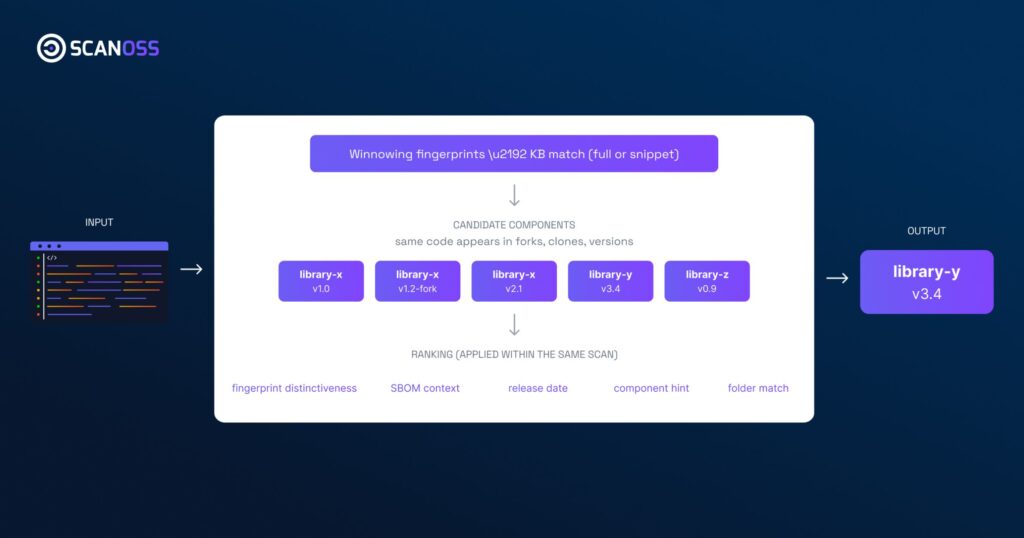
SCANOSS uses the Winnowing algorithm to generate language-independent fingerprints. These fingerprints focus on structure rather than formatting or naming. This allows detection to remain stable even when code is modified.
This approach is particularly effective in environments where code has been copied, refactored, or partially reused, scenarios where traditional dependency-based tools have limited visibility.
High Precision Snippet Matching
SCANOSS adds a second validation layer at the line level. This improves resolution and helps distinguish real reuse from coincidental similarity. This is critical in reducing ambiguous matches.
Context-aware scanning
By ingesting an SBOM, SCANOSS can prioritise matches aligned with known dependencies. This reduces irrelevant associations and improves attribution confidence.
This context layer is increasingly important as organisations move towards continuous compliance models, where SBOMs are expected to reflect real-time system states rather than static snapshots.
High Precision Folder Matching
SCANOSS can identify entire codebases using proximity hashing. This avoids fragmented attribution and reduces unnecessary deep analysis.
Real-world example: where misattribution appears
Consider a common scenario. A developer copies a utility function from an open source project into an internal codebase. Over time, the function is slightly modified.
A traditional SCA tool may detect the code but associate it with multiple possible origins, or fail to associate it entirely if the structure has changed enough.
SCANOSS, by contrast, detects the structural similarity and refines attribution using additional context. Instead of presenting multiple ambiguous matches, it narrows the result to the most probable origin.
This reduces manual validation effort and improves confidence in downstream processes such as licence review or vulnerability triage.
Why does misattribution matter for compliance and risk?
Misattribution is not just a developer inconvenience. It directly impacts governance.
Incorrect attribution can lead to misinterpreted licence obligations, incorrect vulnerability exposure or incomplete or misleading SBOMs.
In regulated environments, this becomes a compliance issue. Frameworks such as the Cyber Resilience Act require organisations to understand the components within their software, not just list them.
If attribution is incorrect, the entire inventory becomes unreliable. This shift is important. Regulation requirements are moving towards demonstrable understanding. It is no longer sufficient to produce an SBOM, organisations must be able to justify its accuracy.
How will attribution accuracy evolve?
The next iteration of SCANOSS fingerprinting removes user-defined identifiers such as variable and function names. This reduces noise and improves consistency across datasets. Future scanning approaches will analyse code in multiple iterations, refining context with each pass. This enables deeper understanding and further reduces misattribution.
A practical evaluation criterion is simple: how much time does your team spend validating results? High validation effort is often a signal of attribution issues rather than detection failures.
What should organisations evaluate in SCA tools?
When assessing SCA tools, the key question is not how many findings are reported.
It is whether those findings can be trusted without extensive manual validation.
A tool that reduces matches may appear cleaner but risks missing relevant code. A tool that detects accurately but misattributes creates operational friction.
The objective is high detection coverage with precise attribution.
Improving attribution requires better context, stronger matching techniques, and continuous refinement based on real-world usage.
SCANOSS provides source-level visibility and attribution mechanisms designed for this purpose. If you want to see how this applies to your environment, explore the platform or request a walkthrough with the team.